Designing and Building a URL Shortener on AWS

If you have been on the internet long enough, you must have come across short URL links that look like this, https://ewal.short/abcd12, which lead you to a website with a longer URL. A short URL is useful when typing a message on platforms that have a character limit, like X or text messaging (SMS). Sometimes, it’s about aesthetics, short URLs look nicer when you add them to a paragraph of text than long ones. It could also be for branding, where you want a consistent look for links shared in your campaigns, so that your customers easily recognize your content. These short links can be created with URL shortening services like Bitly, TinyURL, Short.io. In this post, I discuss how I would design one with AWS services, and how I built it.
TL;DR
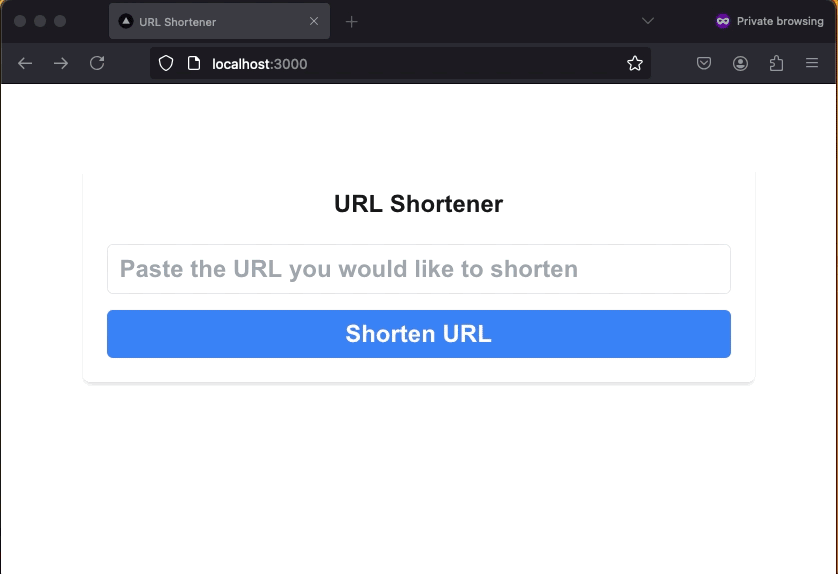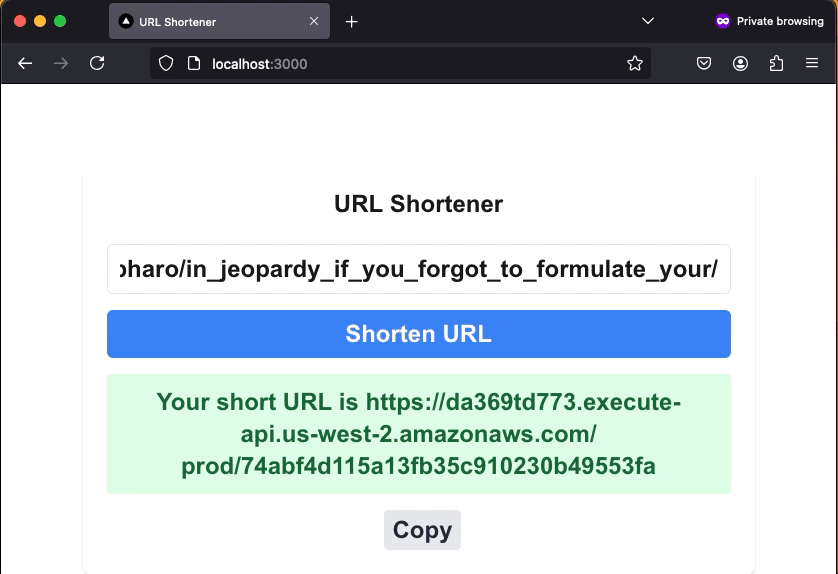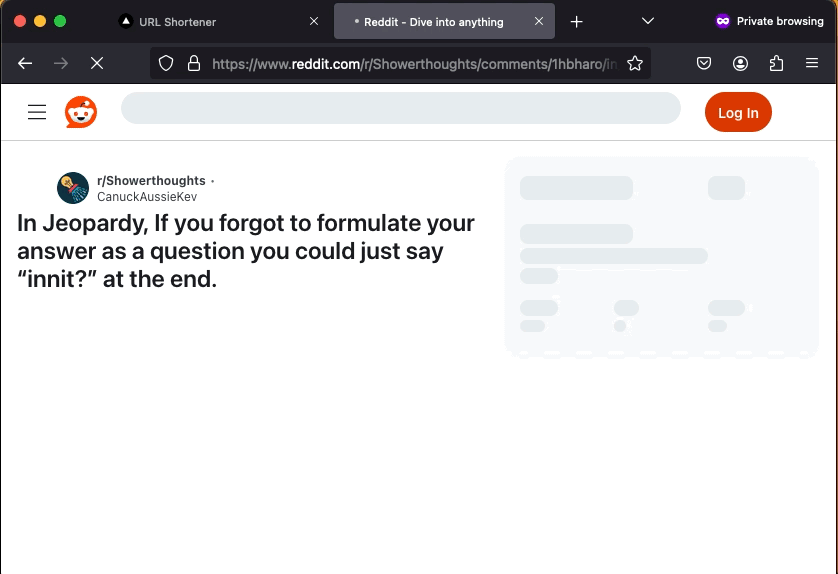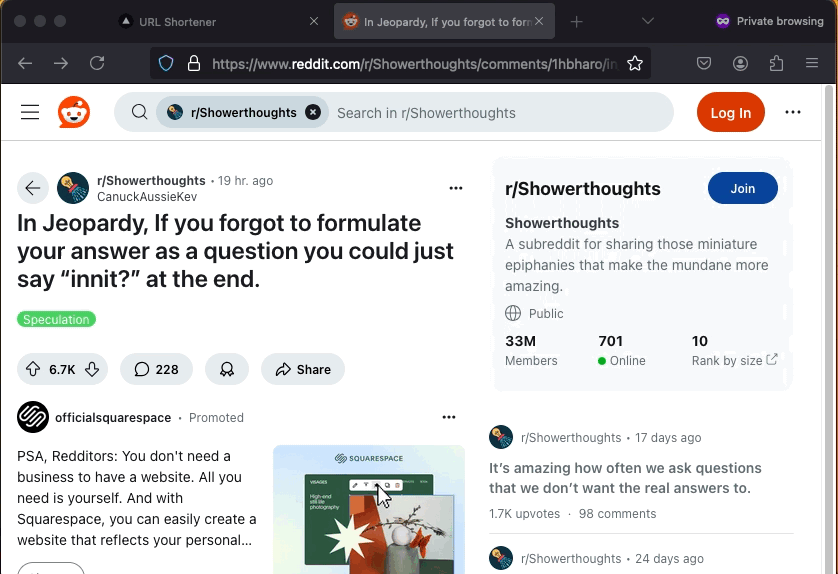
To see what I built, check out the API back-end architecture and functionality in my URL Shortener CDK Back-end GitHub repository. The front-end application is in the URL Shortener Web Application GitHub repository. Deploy the back-end before the front-end. Here’s a demonstration of the final product.
Background
Some years ago, I attended an on-site interview at a tech company. At the time I had built a dockerized Django web application being used by engineers at the company I worked for, as well as other personal projects. The interviewer had asked me to design a URL shortener. I had never done this before and had no idea that it was a popular system design question. My brain started to think about how to solve the problem. I did not know AWS, so I explained everything in on-premise terms. Fortunately, I got that job, and since doing that interview, I’ve gained a lot of cloud and development experience. Now, I want to share how I would design and implement this use-case with AWS services.
Requirements Gathering
The requirements for a system can be split into two parts, functional and non-functional requirements. The functional requirements are what the system must capable of doing at a bare minimum. Non-functional requirements are about the quality of the system, i.e. they are abstract but crucial. Some questions you should ask the client:
- How many users do you anticipate would use the URL shortener?
- How long do you plan to store the shortened URLs for, that is, would they expire?
- If they should have an expiration time, should the users be able to configure this duration?
- How long should the shortened URL be?
- Should I shorten the URL alone, or both the URL and path?
- Are the users concentrated in one geographic location, or are they in multiple locations or countries?
- What is your budget?
- Would you like to manage the underlying infrastructure?
These questions are not an exhaustive list, but are to help you ensure you’re designing the right architecture. It is better to ask too many questions than to build something that the user does not want, or is over-engineered, or expensive. Based on the above, here are the requirements for this system (I’m the client, lol):
Functional requirements
- There would be about 10,000 daily active users (DAUs).
- URLs should be stored for 30 days, and this is not configurable.
- It’s up to you how long the shortened URL should be.
- The users are geographically distributed around the world.
Non-functional requirements
- I want to spend less than $100 per month. Cost is usually a top priority.
- The service should scale for up to 100,000 users.
- It should have 99% availability per year.
- I want to minimize operational overhead as much as possible.
System Design
To satisfy the functional requirements, we need a service that takes the users’ requests and routes them to a compute service that generates short URLs and stores them in a database. The back-end compute service takes these requests and either generates a shortened URL, or returns a shortened URL to the user, or redirects the user to the original URL destination. Finally, there should be a storage service that acts as a source of truth, mapping the shortened URLs to the original ones.
There are a few options that meet the functional requirements, but let’s pick the most fitting per layer.
API request service
For this scenario, the AWS services that can handle and route API requests are Elastic Load Balancer (ELB) and API Gateway. ELB is the generic name for a group of load balancers, including Application Load Balancer (ALB), Network Load Balancer (NLB) and Gateway Load Balancer (GLB). Each type of load balancer suits certain use-cases. On the other hand, API Gateway is a managed service, that provides two different types of APIs, REST API and HTTP API, best for certain use-cases.
- ALB is best when you would like control of the traffic management and routing at the application layer, the seventh layer of the Open Systems Interconnection (OSI) model.
- NLB operates at the transport layer (fourth layer of the OSI model), and is best for high-performance, low-latency, and scalable network-level load balancing.
- GLBs function at the network layer (third layer of the OSI model) and are best for load balancing at the network edge i.e. where two different networks meet each other.
- REST API supports per-client rate limiting, request body transformation, and mock integrations. It gives the developer more flexibility for configuration.
- HTTP APIs are a more affordable option from API Gateway, are best for lower-latency HTTP-based communication than REST APIs, and ideal for use cases where minimal features are required, like proxying requests to a Lambda back-end.
Based on the above, the API Gateway REST API and HTTP API fit best, considering the client wants to minimize operational overhead. However, only the REST API easily allows you serve requests to a geographically distributed user base. The Edge configuration automatically configures a Content Delivery Network (CDN) for the REST API.
Compute service
There are many compute services in AWS that could meet our client’s needs, but we ultimately have to choose one. Some compute services that could work are:
- AWS Lambda is a serverless compute service, best suited for event-driven architectures. It quickly spins up a container with an instance of your code when it receives an event payload. The container is destroyed after some time, so it’s best for short-lived tasks.
- Amazon Elastic Compute Cloud (EC2) provides on-demand virtual machines that can be scaled up or down, based on user-defined conditions. An administrator can define the storage, memory, networking, e.t.c for these virtual servers. Use this for long-running tasks.
- Amazon Elastic Kubernetes Service (EKS) or Elastic Container Service (ECS) are both container orchestration services provided by AWS. They enable you manage multiple containers.
Since the customer wants minimal operational overhead, and wants to reduce cost as much as possible, AWS Lambda is the winner here. Lambda is a fully managed serverless compute service, such that you only pay for each request sent to a function and duration it takes the code to start.
Database service
AWS has a guide on how to pick a database depending on your requirements for an architecture. Considering our client’s requirements, both a Relational and Key-value database would work. However, since there is no need to track relationships between different data entities, a Key-value database like Amazon DynamoDB would suffice. It comes with other benefits like single-digit millisecond performance at any scale, and no need for managing the database yourself, among other things. These fit the customer’s requirements for the expected DAUs and minimal operational overhead.
Architecture

After discussing with the client and gathering enough information of the business and technical requirements, the architecture above should work for the scenario. However, it’s important to get buy-in from the customer. Discuss how a request flows from the first time it hits your architecture through to the end. Talk about the various scenarios: shortening a URL, using a shortened URL, and so on.
In the above architecture, a user makes a HTTP POST request to shorten a URL payload and sends to the REST API, the request is forwarded to Lambda which verifies that there is no existing entry for this URL in the database. If there is an existing entry, it is returned to the user, and if there isn’t, a new one is created. The user can then post the URL in a browser, which would make a HTTP GET request to the API, Lambda would check the database for the original URL destination and redirect the user to that location.
Implementation
I have written and uploaded the back-end functionality to the URL Shortener CDK Back-end GitHub repository, using AWS Cloud Development Kit (CDK) in Typescript. The Lambda function is written in Python. Additionally, I’ve written a Next.js front-end application to consume the API, and uploaded it in the URL Shortener Web Application GitHub repository. The instructions on how to deploy both projects are in the respective repositories.
Cost analysis
API Gateway Costs
- REST API with 10,000 daily users = ~300,000 monthly requests
- API Gateway pricing: $3.50 per million requests
- Estimated monthly cost: ~$1.05
Lambda Costs
- Assuming an average request takes 500ms, and an x86 architecture is being used
- Memory allocation: 128 MB
- 10,000 daily users = 300,000 monthly invocations
- Lambda free tier: 1 million free requests monthly
Compute charge:
- 300,000 requests * 0.5 seconds * (128/1024) GB = 1,8750 GB-seconds
- Estimated monthly compute cost: $0.0000166667 * 1,8750 = ~$0.31
DynamoDB Costs
- Assuming 1 KB per URL mapping, and thrice as many reads versus writes
- On-demand capacity mode
- 300,000 writes per month = 0.3 million write request units
- 3 * 300,000 = 900,000 reads per month = 0.9 million read request units
- Storage requirement: 1 KB * 300,000 items = 300 MB = 0.3 GB
Database charge:
- Estimated monthly cost: (0.3 * 0.625) + (0.9 * 0.125) + (0.25 * 0.3) = ~$0.375
Additional Costs
- CloudWatch Logs (Standard): ~$0.50/month
- Data transfer: Negligible for this scale
Budget Analysis
- Customer’s budget: <$100/month
- Proposed architecture cost: ~$2.235/month
Future improvements
While the current architecture and implementation address the scenario’s business and technical requirements, there are multiple aspects that can be improved to make this a more robust solution.
- Scaling to millions of users: Suppose this service quickly becomes popular such that we have 20 million users, and 2 million daily active users (DAU), people would start experiencing errors and performance issues. DynamoDB can scale up to handle 20 million users’ short URLs and other data, however, Lambda would start hitting concurrency limits and throttling requests from users. You could increase the concurrency quota for Lambda, but that can only go so far. This architecture may need to change. We could replace Lambda with a container service like AWS Fargate for ECS, or EKS. However, we would need to discuss more with the customer, because each technology has unique benefits and drawbacks. In the meantime, check out this video on scaling on AWS.
- Collision handling: The current implementation uses the MD5 hashing algorithm to generate short URLs. MD5 is notorious for occasionally generating the same output hash for different input data, known as a collision. As the number of users that access our API grows, this problem quickly becomes apparent. Hence, a better algorithm for shortening the URLs has to be used. Here is one article that discusses how to handle this situation.
- Ability for users to track their shortened URLs: Users are unable to track shortened URLs that they had previously generated, they have to manually note the short URL generated for any URL that is shortened. This is a less than ideal user experience, people would want to have a view that shows them a list of short URLs they have generated as well as the URL destination it points to. It can be done by adding authentication and session handling so that when a user is logged in, short URLs they have generated can be immediately retrieved in the browser.
Conclusion
There are many ways to skin a cat, the same way there are multiple ways to design a system to solve a problem, based on specified requirements. However, some ways are better than others. The way you design a system depends on the information you gather from the client. I must admit that at the time I did the on-site interview, I did not do proper requirements gathering, but now that I know better, I’ve done better.
References
- Django
- What’s the Difference Between Application, Network, and Gateway Load Balancing?
- What is OSI Model?
- Deciding Where to Host Your API: AWS Lambda vs. AWS EKS
- Choosing an AWS compute service
- Choosing an AWS database service
- Amazon API Gateway pricing
- AWS Lambda pricing
- Amazon DynamoDB - Pricing for On-Demand Capacity
- Amazon CloudWatch Pricing
- AWS re:Invent 2023 - Scaling on AWS for the first 10 million users (ARC206)
- What is MD5? Understanding Message-Digest Algorithms
- Collision handling in our URL shortener service