How I Boost My Productivity Using Large Language Models (LLMs)

There is a lot of fear-mongering regarding Artificial Intelligence (AI), many sources talk about how it would take away jobs. Generative AI particularly, has enjoyed a lot of attention in the past few months. Large Language Models (LLMs) are a popular type of generative AI. These are trained on a large data set, and can generate text, images etc. ChatGPT is one of the popular LLMs used today.
It would be unfair not to acknowledge that some have lost their jobs to AI, I hope they are able to bounce back from this temporary set-back. However, I’d like to focus on the positives that we would see because of AI. What if AI is not the enemy, but a tool that could make you even better than you already are?
With the hype surrounding AI, especially where companies tack it on almost any product for whatever reason, it’s easy to get tired of all the noise and overlook the potential benefits it brings. It is not a magic wand that solves any problem you want. Interestingly, it would only solve your problem if you give it a well-thought-out question, or clear instructions on what you need from it. This means that the user must have a good idea of the problem at hand, and even better, a high-level understanding of how the problem can be solved. Concepts stick better when you tell a story, so I’ll share a personal experience here.
The Scenario
A while ago, I was working an automation project to help solve a problem for multiple teams at scale. The automation had different parts, involving various technologies; Ansible for validation, Jenkins for Continuous Deployment, Python for automating the task. One of the steps, required me to parse a directory of YAML files and update each dictionary (or map) in a list with a specific key-value pair, based on a certain condition. Also, I needed to preserve spaces and comments. While I could have done this in maybe 30 minutes, where I may have to debug syntax errors, include robust-exception handling etc., I opted for a different approach. Since I knew how to solve the problem algorithmically with pseudocode, I decided to share my prompt with the Large Language Model (LLM).
The input data is shown.
metadata:
traveler: "Danny Whizbang"
date_created: "Sep 25, 2024"
destinations:
# CDT means Central Daylight Time
- name: "Big Bend National Park"
location: "Texas"
time_zone: "CDT"
# MDT means Mountain Daylight Time
- name: "Grand Canyon National Park"
location: "Arizona"
time_zone: "MDT"The Approach
To achieve the goal, I put in the prompt below in ChatGPT.
Using Python, parse a directory containing YAML files which could be nested.
For each file and each item in the destinations list, if the time_zone key is MDT,
add a key called visited and set its value to false.
Expected YAML data:
metadata:
traveler: "Danny Whizbang"
date_created: "Sep 25, 2024"
destinations:
# CDT means Central Daylight Time
- name: "Big Bend National Park"
location: "Texas"
time_zone: "CDT"
# MDT means Mountain Daylight Time
- name: "Grand Canyon National Park"
location: "Arizona"
time_zone: "MDT"It returned this result, basically explaining how to run the code.
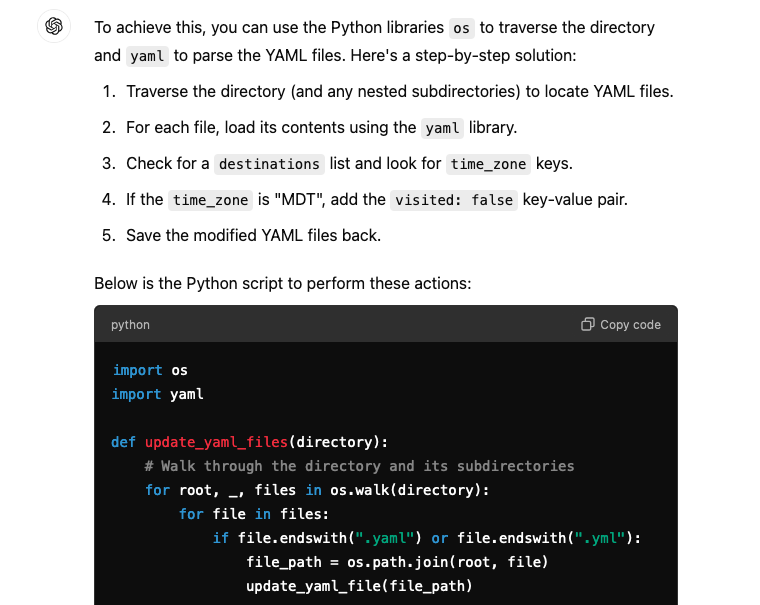
Here’s the returned code snippet.
import os
import yaml
def update_yaml_files(directory):
# Walk through the directory and its subdirectories
for root, _, files in os.walk(directory):
for file in files:
if file.endswith(".yaml") or file.endswith(".yml"):
file_path = os.path.join(root, file)
update_yaml_file(file_path)
def update_yaml_file(file_path):
# Load the YAML content
with open(file_path, 'r') as yaml_file:
try:
data = yaml.safe_load(yaml_file)
except yaml.YAMLError as exc:
print(f"Error reading YAML file {file_path}: {exc}")
return
# Check if 'destinations' exists and process it
if "destinations" in data:
for destination in data["destinations"]:
if destination.get("time_zone") == "MDT":
destination["visited"] = False
# Save the updated YAML content back to the file
with open(file_path, 'w') as yaml_file:
yaml.safe_dump(data, yaml_file)
print(f"Updated file: {file_path}")
else:
print(f"No 'destinations' key found in {file_path}")
# Usage: specify the directory to process
directory_path = '/path/to/your/yaml/files' # Change this to your directory
update_yaml_files(directory_path)In the result, ChatGPT also explains the key elements in the code, as well as what part of the code needs to be updated to get it to run. Once I was done installing the Python dependencies, and updating the directory path, I ran the code and got the output below. Observe how the YAML file has been re-written, such that the spaces and comments are gone, and the keys, metadata and destinations, have been re-arranged. This is an instance where good knowledge of the technology you’re using helps.
destinations:
- location: Texas
name: Big Bend National Park
time_zone: CDT
- location: Arizona
name: Grand Canyon National Park
time_zone: MDT
visited: false
metadata:
date_created: Sep 25, 2024
traveler: Danny WhizbangI wanted the spacing and comments preserved, and the existing format in general, so I asked ChatGPT to update the code, specifying my requirement, so it returned the output below.
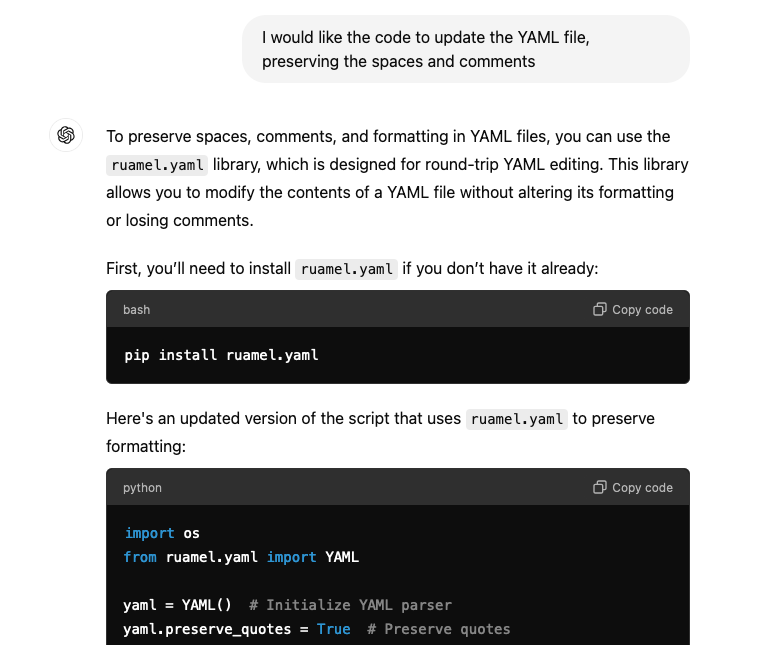
For reference, here’s the new code below.
import os
from ruamel.yaml import YAML
yaml = YAML() # Initialize YAML parser
yaml.preserve_quotes = True # Preserve quotes
def update_yaml_files(directory):
# Walk through the directory and its subdirectories
for root, _, files in os.walk(directory):
for file in files:
if file.endswith(".yaml") or file.endswith(".yml"):
file_path = os.path.join(root, file)
update_yaml_file(file_path)
def update_yaml_file(file_path):
# Load the YAML content
with open(file_path, 'r') as yaml_file:
try:
data = yaml.load(yaml_file)
except Exception as exc:
print(f"Error reading YAML file {file_path}: {exc}")
return
# Check if 'destinations' exists and process it
if "destinations" in data:
modified = False # Flag to check if changes are made
for destination in data["destinations"]:
if destination.get("time_zone") == "MDT":
if "visited" not in destination:
destination["visited"] = False
modified = True
# Save the updated YAML content back to the file if changes were made
if modified:
with open(file_path, 'w') as yaml_file:
yaml.dump(data, yaml_file)
print(f"Updated file: {file_path}")
else:
print(f"No updates needed for {file_path}")
else:
print(f"No 'destinations' key found in {file_path}")
# Usage: specify the directory to process
directory_path = '/path/to/your/yaml/files' # Change this to your directory
update_yaml_files(directory_path)The Outcome
Subsequently, I researched the ruamel.yaml library and this pyyaml behavior, I found that the previous issue was happening because the pyyaml library does not preserve formatting. I then ran the new code, and it worked. The spaces and comments were being preserved!
metadata:
traveler: "Danny Whizbang"
date_created: "Sep 25, 2024"
destinations:
# CDT means Central Daylight Time
- name: "Big Bend National Park"
location: "Texas"
time_zone: "CDT"
# MDT means Mountain Daylight Time
- name: "Grand Canyon National Park"
location: "Arizona"
time_zone: "MDT"
visited: falseConclusion
Imagine how much more time this could have taken if you had written the code yourself, and debugged multiple other issues, including this one. The LLM did a lot of the heavy-lifting, but it’s my knowledge of algorithmic thinking and programming that helped me create clear instructions to achieve the desired goal. This is not to say you couldn’t have done it if you had no knowledge of these, it would have just taken more time. Also, it would be difficult to debug the code if it does not work as expected, and you have no knowledge about what you’re trying to do.
Whether AI is something to be leveraged or feared, is really up to you.